这两天因为一点个人原因写了点好久没碰的python,其中涉及到协程编程,上次搞的时候,它还是web框架tornado特有的feature,现在已经有async await 关键字支持了。思考了一下其实现,回顾了下这些年的演变,觉得还有点意思。
都是单线程,为什么原来低效率的代码用了
asyncawait加一些异步库就变得效率高了?
如果你做基于python的网络或者web开发时,对于这个问题曾感到疑惑,这篇文章会给你答案。
0x00 开始之前
首先,本文不是带你浏览源代码,然后对照原始代码给你讲python标准的实现。相反,我们会从实际问题出发,思考解决问题的方案,一步步体会解决方案的演进路径,最重要的,希望能在过程中获得知识系统性提升。
⚠️ 本文仅是提供此了一个独立的思考方向,并未遵循历史和现有实际具体的实现细节。
其次,阅读这篇文章需要你对python比较熟悉,至少了解python中的生成器generator的概念。
0x01 IO 多路复用
这是性能的关键。但我们这里只解释概念,其实现细节不是重点,这对我们理解python的协程已经足够了,如已足够了解,前进到0x02。
首先,你要知道所有的网络服务程序都是一个巨大的死循环,你的业务逻辑都在这个循环的某个时刻被调用:
def handler(request):
# 处理请求
pass
# 你的 handler 运行在 while 循环中
while True:
# 获取一个新请求
request = accept()
# 根据路由映射获取到用户写的业务逻辑函数
handler = get_handler(request)
# 运行用户的handler,处理请求
handler(request)设想你的web服务的某个handler,在接收到请求后需要一个api调用才能响应结果。对于最传统的网络应用,你的api请求发出去后在等待响应,此时程序停止运行,甚至新的请求也得在响应结束后才进得来。如果你依赖的API请求网络丢包严重,响应特别慢呢?那应用的吞吐量将非常低。
很多传统web服务器使用多线程技术解决这个问题:把handler的运行放到其他线程上,每个线程处理一个请求,本线程阻塞不影响新请求进入。这能一定程度上解决问题,但对于并发比较大的系统,过多线程调度会带来很大的性能开销。
IO多路复用可以做到不使用线程解决问题,它是由操作系统内核提供的功能,可以说专门为这类场景而生。简单来讲,你的程序遇到网络IO时,告诉操作系统帮你盯着,同时操作系统提供给你一个方法,让你可以随时获取到有哪些io操作已经完成。就像这样:
# 操作系统的IO复用示例伪代码
io_register(io_id, io_type) # 向操作系统io注册自己关注的io操作的id和类型
io_register(io_id, io_type)
# 获取完成的io操作, 使用 epoll() in Linux and kqueue() in Unix
events = io_get_finished()
for (io_id, io_type) in events:
if io_type == READ:
data = read_data(io_id)
elif io_type == WRITE:
write_data(io_id,data)把IO复用逻辑融合到我们的服务器中,大概会像这样:
call_backs = {}
def handler(req):
# do jobs here
io_register(io_id, io_type)
def call_back(result):
# 使用返回的result完成剩余工作
call_backs[io_id] = call_back
# 新的循环
while True:
# 获取已经完成的io事件
events = io_get_finished()
for (io_id, io_type) in events:
if io_type == READ: # 读取
data = read(io_id)
call_back = call_backs[io_id]
call_back(data)
else:
# 其他类型io事件的处理
pass
# 获取一个新请求
request = accept()
# 根据路由映射获取到用户写的业务逻辑函数
handler = get_handler(request)
# 运行用户的handler,处理请求
handler(request)我们的handler对于IO操作,注册了回调就立刻返回,同时每次迭代都会对已完成的IO执行回调,网络请求不再阻塞整个服务器。
上面的伪代码仅便于理解,具体实现细节更复杂。而且就连接受新请求也是在从操作系统得到监听端口的IO事件后进行的。我们如果把循环部分还有call_backs字典拆分到单独模块,就能得到一个EventLoop,也就是python标准库 asyncio包中提供的ioloop
0x02 用生成器消除 callback
着重看下我们业务中经常写的handler函数,在有独立的ioloop后,它现在变成类似这样:
def handler(request):
# 业务逻辑代码
# 需要执行一次API请求
def call_back(result):
# 使用API返回的result完成剩余工作
print(result)
# 注册回调,没有io_call这个方法,仅示意,表示注册一个io操作
asyncio.get_event_loop().io_call(api, call_back)到这里,性能问题已经解决了:我们不再需要多线程就能源源不断接受新请求,而且不用care依赖的API响应有多慢。
但是我们也引入了一个新问题,原来流畅的业务逻辑代码现在被拆成了两部分,请求API之前的代码还正常,请求API之后的代码只能写在回调函数里面了。这里我们业务逻辑只有一个API调用,如果有多个API,再加上对redis或者mysql的调用(它们本质也是网络请求),整个逻辑会被拆分的更散,这对业务开发是一笔负担。对于有匿名函数的一些语言(没错就是javascript),还可能会引发所谓的「回调地狱」。接下来我们想办法解决这个问题。
如果函数在运行到网络IO操作处后能够暂停,完成后又能在断点处唤醒就好了。
如果你对python的生成器熟悉,你应该会发现,它恰好具有这个功能:
def example():
value = yield 2
print("get", value)
return value
g = example()
# 使用send(None)启动生成器,我们应该会得到 2
got = g.send(None)
print(got) # 2
try:
# 再次启动 会显示 "get 4", 就是我们传入的值
got = g.send(got*2)
except StopIteration as e:
# 生成器运行完成,将会print(4),e.value 是生成器return的值
print(e.value)函数中有yield关键字,调用函数将会得到一个生成器,生成器一个关键的方法send()可以跟生成器交互。g.send(None) 会运行生成器内代码直到遇到yield,并返回其后的对象,也就是2,生成器代码就停在这里了,直到我们再次执行g.send(got*2),会把2*2也就是4 赋值给yield前面的变量value,然后继续运行生成器代码。 yield在这里就像一扇门,可以把一件东西从这里送出去,也可以把另一件东西拿进来。
如果send让生成器运行到下一个yield前就结束了,send调用会引发一个特殊的异常StopIteration,这个异常自带一个属性value,为生成器return的值。
如果我们把我们的handler用yield关键字转换成一个生成器,运行它来把IO操作的具体内容返回,IO完成后的回调函数中把IO结果放回并恢复生成器运行,那就解决了业务代码不流畅的问题了:
def handler(request):
# 业务逻辑代码
# 需要执行一次API请求,直接把IO请求信息yield出去
result = yield io_info
# 使用API返回的result完成剩余工作
print(result)
# 这个函数注册到ioloop中,用来当有新请求的时候回调
def on_request(request):
# 根据路由映射获取到用户写的业务逻辑函数
handler = get_handler(request)
g = handler(request)
# 首次启动获得io_info
io_info = g.send(None)
# io完成回调函数
def call_back(result):
g.send(result) # 重新启动生成器
asyncio.get_event_loop().io_call(io_info, call_back)上面的例子,用户写的handler代码已经不会被打散到callback 中,on_request函数使用callback和ioloop交互,但它会被实现在web框架中,对用户不可见。上面代码足以给我们提供用生成器消灭的callback的启发,但局限性有两点:
- 业务逻辑中仅发起一次网络IO,但实际中往往更多
- 业务逻辑没有调用其他异步函数(协程),但实际中我们往往会调用其他协程
0x03 解决完整调用链
我们来看一个更复杂的例子:
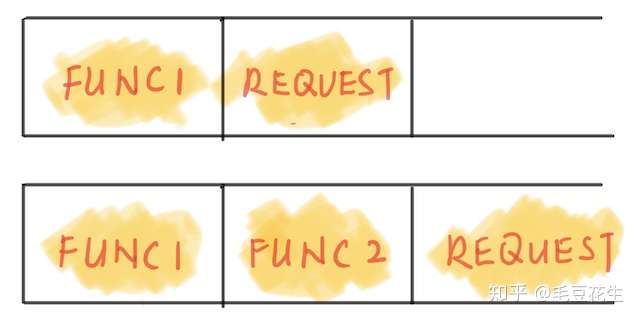
函数调用链路图。
其中request 执行真正的IO,func1 func2 仅调用。显然我们的代码只能写成这样:
def func1():
ret = yield request("http://test.com/foo")
ret = yield func2(ret)
return ret
def func2(data):
result = yield request("http://test.com/"+data)
return result
def request(url):
# 这里模拟返回一个io操作,包含io操作的所有信息,这里用URL简化
result = yield "iojob of %s" % url
return result对于request,我们把IO操作通过yield暴露给框架。对于func1 和 func2,调用request显然也要加yield关键字,否则request调用返回一个生成器后不会暂停,继续执行后续逻辑显然会出错。
这基本就是我们在没有yield from aysnc await时代,在tornado框架中写异步代码的样子。
要运行整个调用栈,大概流程如下: 1. 调用func1()得到生成器 2. 调用send(None)启动它得到会得到request("http://test.com/foo")的结果,还是生成器对象 3. send(None)启动由request()产生的生成器,会得到IO操作,由框架注册到ioloop并指定回调 4. IO完成后的回调函数内唤醒request生成器,生成器会走到return语句结束 5. 捕获异常得到request生成器的返回值,将上一层func1唤醒,同时又得到func2()生成器 6. … 继续执行
对算法和数据结构熟悉的朋友遇到这种前进后退的遍历逻辑,可以递归也可以用栈,因为递归使用生成器还做不到,我们可以使用栈,其实这就是「调用栈」一词的由来。
借助栈,我们可以把整个调用链上串联的所有生成器对表现为一个生成器,对其不断send就能不断得到所有io操作信息并推动调用链前进,实现方法如下:
- 第一个生成器入栈
- 调用
send,如果得到生成器就入栈并进入下一轮迭代 - 遇到到IO请求
yield出来,让框架注册到ioloop - IO操作完成后被唤醒,缓存结果并出栈,进入下一轮迭代,目的让上层函数使用IO结果恢复运行
- 如果一个生成器运行完毕,也需要和4一样让上层函数恢复运行
如果实现出来,代码不长但信息量比较大。他把整个调用链对外变成一个生成器,对其调用send,就能整个调用链中的IO,完成这些IO,继续推动调用链内的逻辑执行,直到整体逻辑结束:
def wrapper(gen):
# 第一层调用 入栈
stack = Stack()
stack.push(gen)
# 开始逐层调用
while True:
# 获取栈顶元素
item = stack.peak()
result = None
if isgenerator(item): # 生成器,
try:
# 尝试获取下个生成器调用,并入栈
# result 初始为None,之后迭代中将为下层调用的返回值
child = item.send(result)
result = None
stack.push(child)
# 入栈后直接进入下次循环,继续深入调用链
continue
except StopIteration as e:
# 如果自己运行结束了,就暂存result,下一步让自己出栈
result = e.value
else: # io 操作
# 遇到了io操作,yield出去
# IO完成后会被用IO结果唤醒并暂存到result
result = yield item
# 走到这里则本层已经执行完毕,出栈,下次迭代将回到调用链上一层
stack.pop()
# 没有上一层的话,那整个调用链都执行完成了,return
if stack.empty():
print("finished")
return result这可能是最复杂的部分,如果一下难以接受可以略过,对于本文理解无碍。只需要知道对于上面示例中的调用链,存在上面这种方法产生如下效果:
w = wrapper(func1())
# 启动 wrpper, 将会得到 "iojob of http://test.com/foo"
w.send(None)
# 上个iojob foo 完成后的结果"bar"传入,继续运行,得到 "iojob of http://test.com/bar"
w.send("bar")
# 上个iojob bar 完成后的结构"barz"传入,继续运行,结束。
w.send("barz")有了这部分以后,框架只需要再加上配套的代码:
# 维护一个就绪列表,存放所有完成的IO事件,格式为(wrapper,result)
ready = []
def on_request(request):
handler = get_handler(request)
# 使用 wrapper 包装后,可以只通过send处理IO了
g = wrapper(func1())
# 把开始状态直接视为结果为None的就绪状态
ready.append((g, None))
# 让ioloop每轮循环都执行此函数,用来处理的就绪的IO,
def process_ready(self):
def call_back(g, result):
ready.append((g, result))
# 遍历所有已经就绪生成器,将其向下推进
for g, result in self.ready:
# 用result唤醒生成器,并得到下一个io操作
io_job = g.send(result)
# 注册io操作
asyncio.get_event_loop().io_call(
io_job,
# 完成后把生成器加入就绪列表,等待下一轮处理
lambda result: ready.append((g, result)
)这里核心思想是维护一个就绪列表,ioloop每轮迭代都来扫一遍,推动就绪的状态的生成器向下运行,并把新的到到IO操作注册,IO完成后再次加入就绪,经过几轮ioloop的迭代一个handler最终会被执行完成。
至此,我们使用生成器写法写业务逻辑已经可以正常运行。
0x04 提高扩展性
如果到这里能读懂,python的协程原理基本就明白了。我们已经实现了一个微型的协程框架,标准库的实现细节跟这里看起来大不一样,但具体的思想是一致的。
我们的协程框架有一个限制,我们只能把IO操作异步化,虽然在网络编程和web编程的世界里,阻塞的基本只有IO操作,但也有一些例外,比如我想让当前操作sleep几秒,用time.sleep()又会让整个线程阻塞住,就需要特殊实现。再比如,可以把一些cpu密集的操作通过多线程异步化,让另一个线程通知事件已经完成后再执行后续。
所以,协程最好能与网络解耦开,让等待网络IO只是其中一种场景,提高扩展性。Python官方的解决方案是让用户自己处理阻塞代码,至于是向ioloop来注册IO事件还是开一个线程完全由你自己,并提供了一个标准「占位符」Future,表示他的结果等到未来才会有,其部分原型如下:
class Future:
# 设置结果
def set_result(result): pass
# 获取结果
def result(): pass
# 表示这个future对象是fou已被设置过结果
def done(): pass
# 设置在他被设置结果时应该执行的回调函数,可以设置多个
def add_done_callback(callback): pass我们的稍加改动就能支持future,让扩展性变得更强。对于用户代码的中的网络请求函数request:
# 现在 request 函数,不是生成器,它返回future
def request(url):
# future 理解为占位符
fut = Future()
def callback(result):
# 当网络IO完成回调的时候给占位符赋值
fut.set_result(result)
# 注册回调
asyncio.get_event_loop().io_call(url, callback)
# 返回占位符
return future现在,request不再是一个生成器,而是直接返回future。而对于位于框架中处理就绪列表的函数:
def process_ready(self):
def callback(fut):
# future被设置结果会被放入就绪列表
ready.append((g, fut.result()))
# 遍历所有已经就绪生成器,将其向下推进
for g, result in self.ready:
# 用result唤醒生成器,得到的不再是io操作,而是future
fut = g.send(result)
# future被设置结果的时候会调用callback
fut.add_done_callback(callback)0x05 发展和变革
许多年前用tornado的时候,大概只有一个yield关键字可用,协程要想实现,就是这么个思路,甚至yield关键字和return关键字不能一个函数里面出现,你要想在生成器运行完后返回一个值,需要手动raise一个异常,虽然效果跟现在return一样,但写起来还是很别扭,不优雅。
后来有了yield from 表达式。他可以做什么?通俗地说,他就是做了上面那个生成器wrapper所做的事:通过栈实现调用链遍历的 ,它是wrapper逻辑的语法糖。有了它,同一个例子你可以这么写:
def func1():
# 注意 yield from
ret = yield from request("http://test.com/foo")
ret = yield from func2(ret)
return ret
def func2(data):
# 注意 yield from
result = yield from request("http://test.com/"+data)
return result
def request(url):
# 同上基于future实现的request
pass然后你就不再需要那个烧脑的wrapper函数了,yield from 背后实现了那段晦涩的逻辑:
g = func1()
# 返回第一个请求的 future
g.send(None)
# 继续运行,进入func2 并得到第它里面的那个future
g.send("bar")
# 继续运行,完成调用链剩余逻辑,抛出StopIteration异常
g.send("barz")yield from直接打通了整个调用链,这已经算是很大的进步了,但是用来异步编程看着还是别扭,其他语言此时已经有专门的协程async await关键字了。终于,再后来的版本把这些内容进一步封装到的async await 关键字,才成为今天比较优雅的样子。
0x06 总结和比较
总的来说,python的原生的协程从两方面实现:
- 基于IO多路复用技术,让整个应用在IO上非阻塞,实现高效率
- 通过生成器让分散的callback代码变成同步代码,减少业务编写困难
有生成器这种对象的语言,其IO协程实现大抵如此,javascript协程的演进基本一模一样,关键字相同,Future类比Promise本质上区别不大。
但是对于以协程闻名的go语言,协程实现跟这个就不同了,它并不基于已有的生成器数据结构。如果要类比的话,可以勉强和python的gevent算作一类,都是自己实现runtime,并patch掉直接的系统调用接入自己的runtime,自己来调度协程,gevent专注于网络相关,基于网络IO调度,比较简单,go实现了完善的多核支持,调度更加复杂和完善,而且创造了基于channel新编程范式。